I've been trying to wrap my head around factor analysis as a
theory for designing and understanding test and survey results. This
has turned out to be another
one of those fields where the going has been a bit rough. I think the
key factors in making these older topics difficult are:
- “Everybody knows this, so we don't need to write up the details.”
- “Hey, I can do better than Bob if I just tweak this knob…”
- “I'll just publish this seminal paper behind a paywall…”
The resulting discussion ends up being overly complicated, and it's
hard for newcomers to decide if people using similar terminology are
in fact talking about the same thing.
Some of the better open sources for background has been Tucker and
MacCallum's “Exploratory Factor Analysis” manuscript and Max
Welling's notes. I'll use Welling's terminology for this
discussion.
The basic idea of factor analsys is to model measurable attributes
as generated by common factors and unique factors.
With and , you get something like:
Relationships between factors and measured attributes
(adapted from Tucker and MacCallum's Figure 1.2)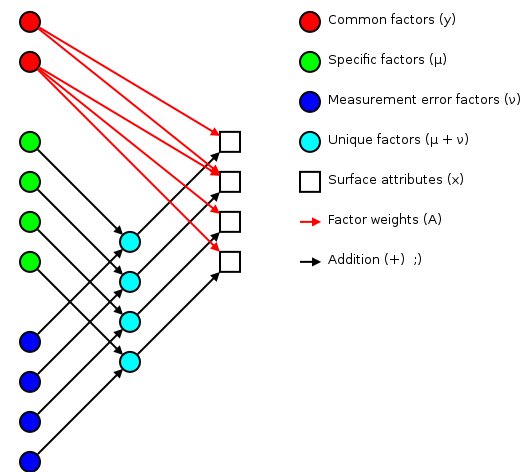 |
Corresponding to the equation (Welling's eq. 1):
(1)
The independent random variables are distributed
according to a Gaussian with zero mean and unit
variance (zero mean because
constant offsets are handled by ; unit variance because
scaling is handled by ). The independent random
variables are distributed according
to , with (Welling's
eq. 2):
(2)
The matrix (linking common factors with measured
attributes \mathbf{\mu}N\mathbf{x}nn^\text{th}\mathbf{A}\mathbf{\Sigma}\mathbf{x}\mathbf{y}\mathbf{\mu}\mathbf{A}\mathbf{\Sigma}\mathbf{A}\mathbf{\Sigma}n\mathbf{A}\rightarrow\mathbf{A}\mathbf{R}\mathbf{A}\mathbf{y}\mathbf{\Sigma}\mathbf{\nu}\mathbf{\Sigma}\mathbf{A}hi^2i^\text{th}x_i\mathbf{y}\mathbf{A} and the
variations contained in the measured scores (why?):
>>> print_row(factor_variance + fa.sigma)
0.89 0.56 0.57 1.51 0.89 1.21 1.23 0.69
>>> print_row(scores.var(axis=0, ddof=1)) # total variance for each question
0.99 0.63 0.63 1.66 0.99 1.36 1.36 0.75
The proportion of total variation explained by the
common factors is given by:
(9)
Varimax rotation
As mentioned earlier, factor analysis generated loadings
that are unique up to an arbitrary rotation (as you'd
expect for a -dimensional Gaussian ball of factors ).
A number of of schemes have been proposed to simplify the initial
loadings by rotating to reduce off-diagonal terms. One
of the more popular approaches is Henry Kaiser's varimax rotation
(unfortunately, I don't have access to either his thesis or
the subsequent paper). I did find (via
Wikipedia) Trevor Park's notes which have been
very useful.
The idea is to iterate rotations to maximize the raw varimax criterion
(Park's eq. 1):
(10)
Rather than computing a -dimensional rotation in one sweep, we'll
iterate through 2-dimensional rotations (on successive column pairs)
until convergence. For a particular column pair , the
rotation matrix is the usual rotation matrix:
(11)
where the optimum rotation angle is (Park's eq. 3):
(12)
where .
Nomenclature
- The element from the row and
column of a matrix . For example here is a 2-by-3
matrix terms of components:
(13)
- The transpose of a matrix (or vector) .
- The inverse of a matrix .
- A matrix containing only the diagonal elements of
, with the off-diagonal values set to zero.
- Expectation value for a function of a random variable
. If the probability density of is
, then . For example,
.
- The mean of a random variable is given by
.
- The covariance of a random variable is given by
. In the factor analysis
model discussed above, is restricted to a
diagonal matrix.
-
- A Gaussian probability density for the random variables
with a mean and a covariance
.
(14)
- Probability of occurring given that
occured. This is commonly used in Bayesian
statistics.
- Probability of and occuring
simultaneously (the joint density).
- The angle of in the complex plane.
.
Note: if you have trouble viewing some of the more obscure Unicode
used in this post, you might want to install the STIX fonts.