Teaching pages (Physics and related topics).
I've been trying to wrap my head around factor analysis as a theory for designing and understanding test and survey results. This has turned out to be another one of those fields where the going has been a bit rough. I think the key factors in making these older topics difficult are:
- “Everybody knows this, so we don't need to write up the details.”
- “Hey, I can do better than Bob if I just tweak this knob…”
- “I'll just publish this seminal paper behind a paywall…”
The resulting discussion ends up being overly complicated, and it's hard for newcomers to decide if people using similar terminology are in fact talking about the same thing.
Some of the better open sources for background has been Tucker and MacCallum's “Exploratory Factor Analysis” manuscript and Max Welling's notes. I'll use Welling's terminology for this discussion.
The basic idea of factor analsys is to model measurable attributes as generated by common factors and unique factors. With and , you get something like:
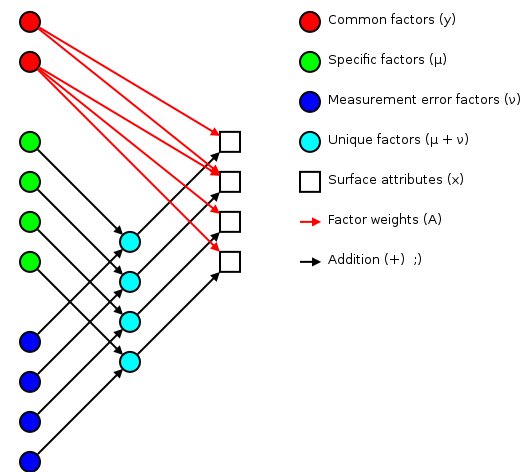 |
Corresponding to the equation (Welling's eq. 1):
The independent random variables are distributed according to a Gaussian with zero mean and unit variance (zero mean because constant offsets are handled by ; unit variance because scaling is handled by ). The independent random variables are distributed according to , with (Welling's eq. 2):
The matrix (linking common factors with measured attributes \mathbf{\mu}N\mathbf{x}nn^\text{th}\mathbf{A}\mathbf{\Sigma}\mathbf{x}\mathbf{y}\mathbf{\mu}\mathbf{A}\mathbf{\Sigma}\mathbf{A}\mathbf{\Sigma}n\mathbf{A}\rightarrow\mathbf{A}\mathbf{R}\mathbf{A}\mathbf{y}\mathbf{\Sigma}\mathbf{\nu}\mathbf{\Sigma}\mathbf{A}hi^2i^\text{th}x_i\mathbf{y}\mathbf{A} and the variations contained in the measured scores (why?):
>>> print_row(factor_variance + fa.sigma)
0.89 0.56 0.57 1.51 0.89 1.21 1.23 0.69
>>> print_row(scores.var(axis=0, ddof=1)) # total variance for each question
0.99 0.63 0.63 1.66 0.99 1.36 1.36 0.75
The proportion of total variation explained by the common factors is given by:
Varimax rotation
As mentioned earlier, factor analysis generated loadings that are unique up to an arbitrary rotation (as you'd expect for a -dimensional Gaussian ball of factors ). A number of of schemes have been proposed to simplify the initial loadings by rotating to reduce off-diagonal terms. One of the more popular approaches is Henry Kaiser's varimax rotation (unfortunately, I don't have access to either his thesis or the subsequent paper). I did find (via Wikipedia) Trevor Park's notes which have been very useful.
The idea is to iterate rotations to maximize the raw varimax criterion (Park's eq. 1):
Rather than computing a -dimensional rotation in one sweep, we'll iterate through 2-dimensional rotations (on successive column pairs) until convergence. For a particular column pair , the rotation matrix is the usual rotation matrix:
where the optimum rotation angle is (Park's eq. 3):
where .
Nomenclature
- The element from the row and
column of a matrix . For example here is a 2-by-3
matrix terms of components:
(13)
- The transpose of a matrix (or vector) .
- The inverse of a matrix .
- A matrix containing only the diagonal elements of , with the off-diagonal values set to zero.
- Expectation value for a function of a random variable . If the probability density of is , then . For example, .
- The mean of a random variable is given by .
- The covariance of a random variable is given by . In the factor analysis model discussed above, is restricted to a diagonal matrix.
- A Gaussian probability density for the random variables
with a mean and a covariance
.
(14)
- Probability of occurring given that occured. This is commonly used in Bayesian statistics.
- Probability of and occuring simultaneously (the joint density).
- The angle of in the complex plane. .
Note: if you have trouble viewing some of the more obscure Unicode used in this post, you might want to install the STIX fonts.
Available in a git repository.
Repository: catalyst-swc
Browsable repository: catalyst-swc
Author: W. Trevor King
Catalyst is a release-building tool for Gentoo. If you use Gentoo and want to roll your own live CD or bootable USB drive, this is the way to go. As I've been wrapping my head around catalyst, I've been pushing my notes upstream. This post builds on those notes to discuss the construction of a bootable ISO for Software Carpentry boot camps.
Getting a patched up catalyst
Catalyst has been around for a while, but the user base has been fairly small. If you try to do something that Gentoo's Release Engineering team doesn't do on a regular basis, built in catalyst support can be spotty. There's been a fair amount of patch submissions an gentoo-catalyst@ recently, but patch acceptance can be slow. For the SWC ISO, I applied versions of the following patches (or patch series) to 37540ff:
- chmod +x all sh scripts so they can run from the git checkout
- livecdfs-update.sh: Set XSESSION in /etc/env.d/90xsession
- Fix livecdfs-update.sh startx handling
Configuring catalyst
The easiest way to run catalyst from a Git checkout is to setup a local config file. I didn't have enough hard drive space on my local system (~16 GB) for this build, so I set things up in a temporary directory on an external hard drive:
$ cat catalyst.conf | grep -v '^#\|^$'
digests="md5 sha1 sha512 whirlpool"
contents="auto"
distdir="/usr/portage/distfiles"
envscript="/etc/catalyst/catalystrc"
hash_function="crc32"
options="autoresume kerncache pkgcache seedcache snapcache"
portdir="/usr/portage"
sharedir="/home/wking/src/catalyst"
snapshot_cache="/mnt/d/tmp/catalyst/snapshot_cache"
storedir="/mnt/d/tmp/catalyst"
I used the default values for everything except sharedir,
snapshot_cache, and storedir. Then I cloned the catalyst-swc
repository into /mnt/d/tmp/catalyst.
Portage snapshot and a seed stage
Take a snapshot of the current Portage tree:
# catalyst -c catalyst.conf --snapshot 20130208
Download a seed stage3 from a Gentoo mirror:
# wget -O /mnt/d/tmp/catalyst/builds/default/stage3-i686-20121213.tar.bz2 \
> http://distfiles.gentoo.org/releases/x86/current-stage3/stage3-i686-20121213.tar.bz2
Building the live CD
# catalyst -c catalyst.conf -f /mnt/d/tmp/catalyst/spec/default-stage1-i686-2013.1.spec
# catalyst -c catalyst.conf -f /mnt/d/tmp/catalyst/spec/default-stage2-i686-2013.1.spec
# catalyst -c catalyst.conf -f /mnt/d/tmp/catalyst/spec/default-stage3-i686-2013.1.spec
# catalyst -c catalyst.conf -f /mnt/d/tmp/catalyst/spec/default-livecd-stage1-i686-2013.1.spec
# catalyst -c catalyst.conf -f /mnt/d/tmp/catalyst/spec/default-livecd-stage2-i686-2013.1.spec
isohybrid
To make the ISO bootable from a USB drive, I used isohybrid:
# cp swc-x86.iso swc-x86-isohybrid.iso
# isohybrid iso-x86-isohybrid.iso
You can install the resulting ISO on a USB drive with:
# dd if=iso-x86-isohybrid.iso of=/dev/sdX
replacing replacing X with the appropriate drive letter for your USB
drive.
With versions of catalyst after d1c2ba9, the isohybrid call is
built into catalysts ISO construction.
SymPy is a Python library for symbolic mathematics. To give you a feel for how it works, lets extrapolate the extremum location for given a quadratic model:
and three known values:
Rephrase as a matrix equation:
So the solutions for , , and are:
Now that we've found the model parameters, we need to find the coordinate of the extremum.
which is zero when
Here's the solution in SymPy:
>>> from sympy import Symbol, Matrix, factor, expand, pprint, preview
>>> a = Symbol('a')
>>> b = Symbol('b')
>>> c = Symbol('c')
>>> fa = Symbol('fa')
>>> fb = Symbol('fb')
>>> fc = Symbol('fc')
>>> M = Matrix([[a**2, a, 1], [b**2, b, 1], [c**2, c, 1]])
>>> F = Matrix([[fa],[fb],[fc]])
>>> ABC = M.inv() * F
>>> A = ABC[0,0]
>>> B = ABC[1,0]
>>> x = -B/(2*A)
>>> x = factor(expand(x))
>>> pprint(x)
2 2 2 2 2 2
a *fb - a *fc - b *fa + b *fc + c *fa - c *fb
---------------------------------------------
2*(a*fb - a*fc - b*fa + b*fc + c*fa - c*fb)
>>> preview(x, viewer='pqiv')
Where pqiv is the executable for pqiv, my preferred image
viewer. With a bit of additional factoring, that is:
Since I love both teaching and open source development, I suppose it was only a matter of time before I attempted a survey of open source text books. Here are my notes on the projects I've come across so far:
Light and Matter
The Light and Matter series is a set of six texts by Benjamin Crowell at Fullerton College in California. The series is aimed at the High School and Biology (i.e. low calc) audience. The source is distributed in LaTeX and versioned in Git. I love this guy!
Crowell also runs a book review site The Assayer, which reviews free books.
Radically Modern Introductory Physics
Radically Modern Introductory Physics is David J. Raymond's modern-physics-based approach to introductory physics. He posts the LaTeX source, but it does not seem to be version controlled.
Calculus Based Physics
Calculus Based Physics, by Jeffrey W. Schnick at St. Anselm in New Hampshire. It is under the Creative Commons Attribution-ShareAlike 3.0 License, and the sources are free to alter. However, there is no official version control, and the sources are in MS Word format :(. On the other hand, I wholeheartedly agree with all the objectives Schnick lists in his motivational note.
Textbook Revolution
Calculus Based Physics' Schnick linked to Textbook Revolution, which immediately gave off good tech vibes with an IRC node (#textbookrevolution). The site is basically a wiki with a browsable list of pointers to open textbooks. The list isn't huge, but it does prominently display copyright information, which makes it easier to separate the wheat from the chaff.
College Open Textbooks
College Open Textbooks provides another registry of open textbooks with clearly listed license information. They're funded by The William and Flora Hewlett Foundation (of NPR underwriting fame).
MERLOT's Open Textbook Initiative
The Multimedia Educational Resource for Learning and Online Teaching (MERLOT) is a California-based project that assembles educational resources. They have a large collection of open textbooks in a variety of fields. The Light and Matter series is well represented. Unfortunately, many of the texts seem to be "free as in beer" not "free as in freedom".
Open Access Textbooks
The Open Access Textbooks project is run by a number of Florida-based groups and funded by the U.S. Department of Education. However, I have grave doubts about any open source project that opens their project discussion with
Numerous issues that impact open textbook implementation (such as creating sustainable review processes and institutional reward structures) have yet to be resolved. The ability to financially sustain a large scale open textbook effort is also in question.
There are zounds of academics with enough knowledge and invested interest in developing an open source textbook. The resources (computers and personal websites) are generally already provided by academic institutions. Just pick a framework (LaTeX, HTML, ...), put the whole thing in Git, and start hacking. The community will take it from there.
Anyhow, everything I've read about this project smells like a bunch of bureaucrats churning out sound bytes.
ArXiv
Finally, there are a number of textbooks on arXiv. For example, Siegel's Introduction to string field theory and Fields are posted source and all. The source will probably be good quality, but the licensing information may be unclear.
Available in a git repository.
Repository: parallel_computing
Browsable repository: parallel_computing
Author: W. Trevor King
In contrast to my course website project, which is mostly about constructing a framework for automatically compiling and installing LaTeX problem sets, Prof. Vallières' Parallel Computing course is basically an online textbook with a large amount of example software. In order to balance between to Prof. Vallières' original and my own aesthetic, I rolled a new solution from scratch. See my version of his Fall 2010 page for a live example.
Differences from my course website project:
- No PHP, since there is no dynamic content that cannot be handled with SSI.
- Less installation machinery. Only a few build/cleanup scripts to
avoid versioning really tedious bits. The repository is designed to
be dropped into your
~/public_html/whole, while the course website project is designed torsyncthe built components up as they go live. - Less LaTeX, more XHTML. It's easier to edit XHTML than it is to exit and compile LaTeX, and PDFs are large and annoying. As a computing class, there are fewer graphics than there are in an intro-physics class, so the extra power of LaTeX is not as useful.
Available in a git repository.
Repository: course
Browsable repository: course
Author: W. Trevor King
Over a few years as a TA for assorted introductory physics classes,
I've assembled a nice website framework with lots of problems using my
LaTeX problempack package, along with some handy Makefiles,
a bit of php, and SSI.
The result is the course package, which should make it very easy to
whip up a course website, homeworks, etc. for an introductory
mechanics or E&M class (431 problems implemented as of June 2012).
With a bit of work to write up problems, the framework could easily be
extended to other subjects.
The idea is that a course website consists of a small, static HTML
framework, and a bunch of content that is gradually filled in as the
semester/quarter progresses. I've put the HTML framework in the
html/ directory, along with some of the write-once-per-course
content (e.g. Prof & TA info). See html/README for more information
on the layout of the HTML.
The rest of the directories contain the code for compiling material
that is deployed as the course progresses. The announcements/
directory contains the atom feed for the course, and possibly a list
of email addresses of people who would like to (or should) be notified
when new announcements are posted. The latex/ directory contains
LaTeX source for the course documents for which it is available, and
the pdf/ directory contains PDFs for which no other source is
available (e.g. scans, or PDFs sent in by Profs or TAs who neglected
to include their source code).
Note that because this framework assumes the HTML content will be relatively static, it may not be appropriate for courses with large amounts of textbook-style content, which will undergo more frequent revision. It may also be excessive for courses that need less compiled content. For an example of another framework, see my branch of Prof. Vallières' Parallel Computing website.
Available in a git repository.
Repository: problempack
Browsable repository: problempack
Author: W. Trevor King
I've put together a LaTeX package problempack to make it easier
to write up problem sets with solutions for the classes I TA.
problempack.sty
The package takes care of a few details:
- Make it easy to compile one pdf with only the problems and another pdf with problems and solutions.
- Define nicely typeset environments for automatically or manually numbered problems.
- Save retyping a few of the parameters (course title, class title,
etc), that show up in the note title and also need to go out to
pdftitleandpdfsubject. - Change the page layout to minimize margins (saves paper on printing).
- Set the spacing between problems (e.g. to tweak output to a single page, versions >= 0.2).
- Add section level entries to the table-of-contents and hyperref bookmarks (versions >= 0.3).
The basic idea is to make it easy to write up notes. Just install
problempack.sty in your texmf tree, and then use it like I do in
the example included in the package. The example produces a simple
problem set (probs.pdf) and solution notes (sols.pdf).
For a real world example, look at my Phys 102 notes with and without solutions (source). Other notes produced in this fashion: Phys201 winter 2009, Phys201 spring 2009, and Phys102 summer 2009.
wtk_cmmds.sty
A related package that defines some useful physics macros (\U, \E,
\dg, \vect, \ihat, ...) is my wtk_cmmds.sty. This used to be a
part of problempack.sty, but the commands are less general, so I
split them out into their own package.
wtk_format.sty
The final package in the problempack repository is wtk_format.sty,
which adjusts the default LaTeX margins to pack more content into a
single page.
I've had a few students confused by this sort of "zooming and chunking" approach to analyzing functions specifically, and technical problems in general, so I'll pass the link on in case you're interested. Curtesy of Charles Wells.